What Even Is Big O? (And Why Should You Care?)
Let me start with a confession: when I first heard "Big O notation," I thought it was some kind of advanced math thing that only computer science professors cared about. Spoiler alert — I was wrong. Dead wrong.
Big O notation is simply a way to describe how your code slows down as the input gets bigger. That is it. Nothing more, nothing less.
Think about it this way. You write a function that works perfectly with 10 items. Great. But what happens when your boss says "hey, we now have 10 million users"? Does your function still work in milliseconds? Or does it choke and die?
That is exactly what Big O tells you. It is the answer to: "How does my code behave at scale?"
Why This Matters in the Real World
Here is a real scenario I have seen happen. A developer writes a search function using nested loops. It works fine during testing with 100 items. Then it hits production with 100,000 items. The page takes 47 seconds to load. Users leave. Money is lost.
If that developer had understood Big O, they would have known their O(n²) solution was a ticking time bomb — and they would have reached for a hash map (O(1) lookup) instead.
Big O is not academic theory. It is a survival skill for writing code that actually works in production.
The One Rule That Simplifies Everything
Here is the beautiful part about Big O — you do NOT need to count every single operation. You just need to identify the dominant term and drop everything else:
O(3n + 500)simplifies to O(n) — constants do not matter at scaleO(n² + 5n + 100)simplifies to O(n²) — the biggest term winsO(500)simplifies to O(1) — any fixed number of steps is constant time- Two Sum — Can you do it in O(n) instead of O(n²)?
- Binary Search — The textbook O(log n) algorithm
- Contains Duplicate — Compare O(n²) brute force vs O(n) hash set
- Maximum Subarray — Kadane's algorithm achieves O(n)
- Merge Sort — Understand why divide-and-conquer gives O(n log n)
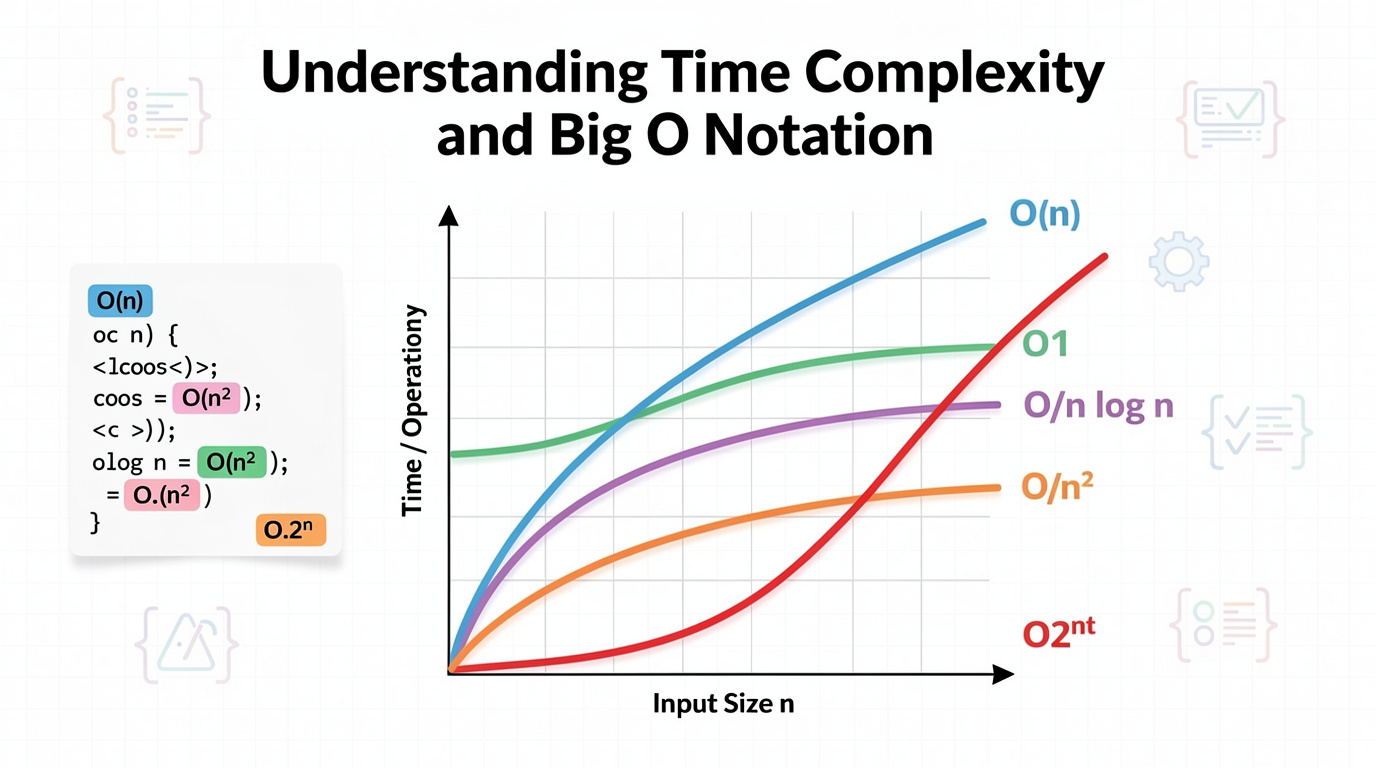
- O(1) is instant. O(log n) is almost instant. O(n) is fair. O(n log n) is the best sorting can do. O(n²) is dangerous. O(2ⁿ) is a disaster.
- Count the loops. Drop the constants. Keep the biggest term.
- When your code is slow, the first question to ask is: "What is the Big O of this?"
Why? Because Big O describes behavior at scale. When n is tiny, everything is fast. When n is huge, only the dominant term matters.
See It in Action
The interactive chart below shows all 6 common complexities plotted together. Press play to step through each one, or use the arrows to go manually. Watch how O(2^n) explodes off the chart while O(1) stays completely flat — that is the difference Big O captures:
<iframe src="/en/dsa/embed.html?topic=0&lang=en" width="100%" height="200" style="border:none;border-radius:12px;overflow:hidden" loading="lazy"></iframe>
Breaking Down Each Complexity (With Real Examples)
Now let me walk you through each complexity class, from the fastest to the slowest. For each one, I will explain what it means, where you see it in real code, and why it matters.
O(1) — Constant Time: The Holy Grail
What it means: No matter how big your input is — 10 items or 10 billion items — the operation takes the same amount of time.
Where you see it: Array access by index, hash map lookups, pushing to a stack.
Why it matters: If you can solve a problem in O(1), you have basically won. Your code will handle any scale without breaking a sweat.
O(log n) — Logarithmic: Incredibly Fast
What it means: Each step cuts the remaining work in half. 1 million items? About 20 steps. 1 billion items? About 30 steps.
Where you see it: Binary search, balanced binary tree operations, finding an item in a sorted array.
Why it matters: Almost as good as O(1) in practice. The growth is so slow that even for enormous inputs, the number of steps stays tiny.
O(n) — Linear: Fair and Honest
What it means: The time grows directly with the input. 10 items = 10 steps. 1 million items = 1 million steps.
Where you see it: Looping through an array once, finding the max/min, counting elements.
Why it matters: If you need to look at every item at least once, O(n) is the best you can achieve. It is the baseline.
O(n log n) — Linearithmic: The Sorting Sweet Spot
What it means: Slightly worse than linear. For each of the n items, you do a log n operation.
Where you see it: Merge sort, quick sort, heap sort — all the good sorting algorithms.
Why it matters: Proven to be the theoretical limit for comparison-based sorting. You cannot sort faster than this.
O(n²) — Quadratic: The Silent Killer
What it means: Time grows as the square of the input. 10 items = 100 steps. 1,000 items = 1,000,000 steps.
Where you see it: Nested loops, bubble sort, selection sort, insertion sort.
Why it matters: Feels fine with small inputs but explodes catastrophically as n grows. This is where beginners get burned most often.
O(2ⁿ) — Exponential: Run Away
What it means: Every additional item DOUBLES the total work. 10 items = 1,024 steps. 20 items = over 1 million. 30 items = over 1 billion.
Where you see it: Generating all subsets, brute-force password cracking, recursive Fibonacci without memoization.
Why it matters: Unless your input is guaranteed to be tiny (n < 25), avoid this at all costs. It does not scale. Period.
Code Examples: Seeing Complexity in Action
How to read these examples: I have added comments showing how many times each line runs. Count the loops — that is your complexity.
Python Examples
# O(1) - Constant: just one direct access, no loops def get_first(arr: list): return arr[0] if arr else None # Always 1 step# O(n) - Linear: one loop through all items def find_max(arr: list) -> int: max_val = arr[0] # 1 step for num in arr: # n times if num > max_val: max_val = num return max_val
# O(n²) - Quadratic: nested loops = n × n def has_duplicate(arr: list) -> bool: for i in range(len(arr)): # n times for j in range(i + 1, len(arr)): # × n times if arr[i] == arr[j]: return True return False # Better approach: use a set for O(n)!
Java Examples
// O(1) - Constant: direct array access public static int getFirst(int[] arr) { return arr[0]; // Always 1 step }// O(n) - Linear: single loop public static int findMax(int[] arr) { int max = arr[0]; for (int num : arr) { // n times if (num > max) max = num; } return max; }
// O(n²) - Quadratic: nested loops public static boolean hasDuplicate(int[] arr) { for (int i = 0; i < arr.length; i++) { // n times for (int j = i + 1; j < arr.length; j++) { // × n times if (arr[i] == arr[j]) return true; } } return false; }
How to Determine the Complexity of Any Code
1. Count the loops. No loops = O(1). One loop = O(n). Two nested = O(n²). 2. Check if loops halve the data. If each iteration cuts remaining work in half, that is O(log n). 3. Look for recursion. Function calls itself twice per call? Probably O(2ⁿ). 4. Drop constants and lower terms. O(3n + 10) = O(n). O(n² + n) = O(n²). 5. Name it. O(1) constant, O(log n) logarithmic, O(n) linear, O(n log n) linearithmic, O(n²) quadratic, O(2ⁿ) exponential.
Practice Problems
Wrapping Up
Big O is one of those concepts that sounds intimidating but is actually straightforward once you get the intuition:
In the next post, we will talk about space complexity — because fast code that eats all your RAM is not much better than slow code. See you there.
